Python: Web Mining - Tatort
Heute möchte ich Euch zeigen, was mir am meisten Spaß bei der Entwicklung von Web Mining Tools mit Python macht. Und damit wir auch von Anfang an im Flow bleiben, setzt dieses Tutorial voraus:
- Eine lauffähige Jupyter-Lab Umgebung für den 1:1 Vergleich mit den Screenshots. Wobei aber auch eine normale Python 3.x Entwicklungsumgebung ausreicht.
- Jupyter-Lab Installation
- extern: anleitung_jupyter_installieren_notebooks.pdf
- extern: https://jupyter.org/install (Installationsbefehle)
- Eclipse mit PyDev Installation
- VSCode Installation
- Jupyter-Lab Installation
- Via import verfügbare Python Module
- bs4 extern: https://pypi.org/project/bs4
- requests extern: https://pypi.org/project/requests
- Grundlegende Kenntnisse zur HTML-Dokument Struktur insbesondere HTML-Tags
Thematisch soll es heute um die Münsteraner Tatort-Serie gehen. Und ich fragte mich neulig, welche Tatort Folgen der Reihe es überhaupt gibt. Fündig wurde ich dann bei Wikipedia unter der Adresse:
https://de.wikipedia.org/wiki/Thiel_und_Boerne#Folgen.
Und von dem persönlichen Nutzen überzeugt, sollte nun für jede Folge eine Text-Datei her. Wie?
Nun ein Blick in die Liste zeigte zwar, dass die Aufgabe grundsätzlich mit überschaubarem Aufwand manuell zu erledigen wäre, aber Spaß sieht doch irgendwie etwas anders aus. Viel spannender hingegen schien mir die Frage:
Wie viele Zeilen Quell-Code benötigt eine automatisierte Lösung?
Um es vorweg zu nehmen, die nachfolgende mini-Lösung benötigt gerade einmal 14 reine Befehlszeilen. Sie lädt dabei die Wikipedia Seite des Münsteraner Tatort herunter, extrahiert aus der Folgen Liste jeweils Nummer sowie Titel und erstellt, wenn noch nicht vorhanden, die dazu passend benannte Text-Datei.
Web Mining
Für den ersten Eindruck vom Daten Material hilft uns zunächst der Web-Browser weiter. Hier exemplarisch Brave, der auf der Chrome-Engine basiert.
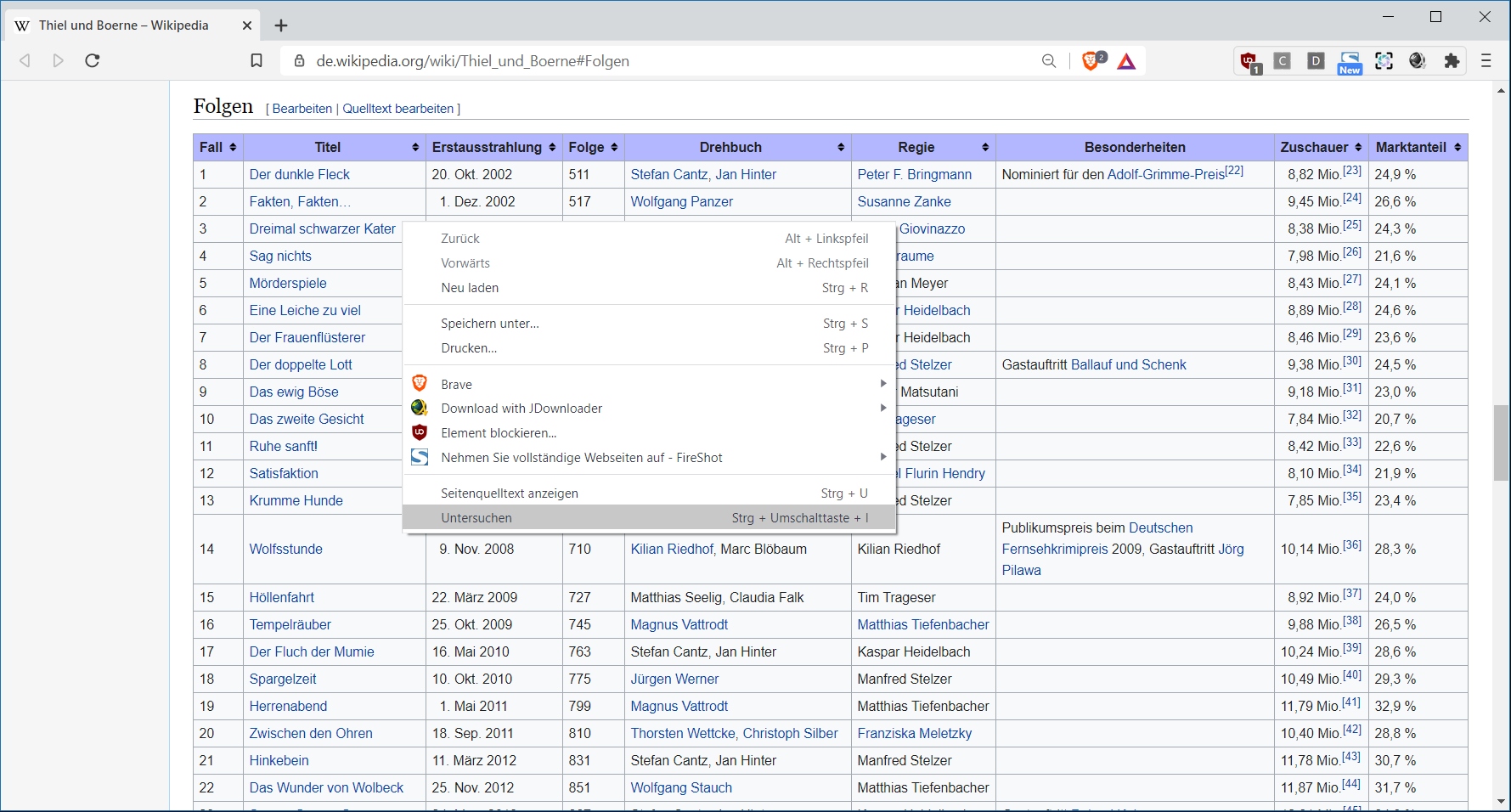
Ein beliebiger Titel aus der Liste lässt sich per Kontext-Menü Eintrag (rechts-Klick): „untersuchen“ und mit dem Debugger des Browsers genauer in Augenschein nehmen.

Hier kann man sehen, dass eine Zeile HTML-typisch durch <tr> .. </tr> Tags beschrieben wird. Und in dieser Zeile geben <td> .. </td> Tags die einzelnen Spaltenwerte wieder. Solltest Du noch einen Crash-Kurs für HTML-Basics benötigen, finden sich hilfreiche Informationen unter anderem hier auf selfhtml.org:
https://wiki.selfhtml.org/wiki/HTML/Tutorials/Einstieg
Witziger Weise kommt man in unserem Fall auch ganz gut ohne tieferes HTML-Verständnis aus. Denn es reicht im Prinzip zu wissen, dass unsere Web-Seite eine Baumstruktur wie ein Festplatten-Laufwerk aufweist. Anstatt der Verzeichnis Namen auf der Platte, bilden auf der Web-Seite HTML-Tags die Struktur-Elemente (Knoten). Um also eine Zeile unserer Liste ausfindig zu machen (Wird durch <tr> Tag beschrieben), müssen wir nur das übergeordnete <tbody> Element im Dokument finden und von dort aus alle untergeordneten <tr> und <td> Tags auslesen.
Aber leider hat die Web-Seite mehr als ein <tbody> Element, weshalb wir einen anderen Ankerpunkt brauchen von dem wir unsere Suche im Dokument-Baum ausgehen lassen können.
Dieser findet sich nur wenige Zeilen über unserem ersten Untersuchungs-Objekt. Ein <span> Tag mit id=“Folgen“:
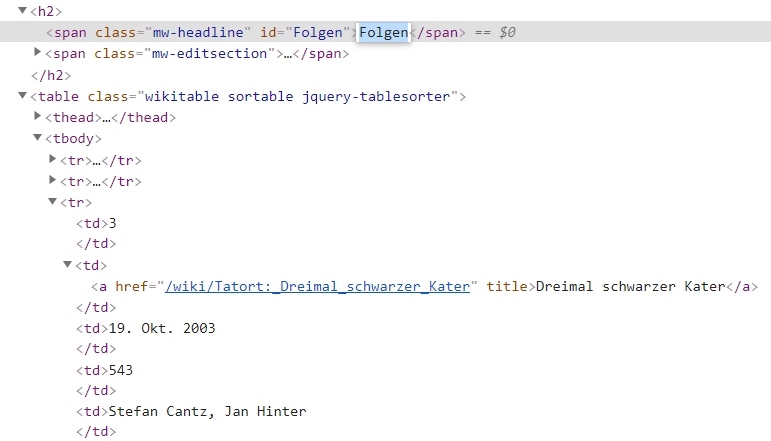
Nach id lassen sich Tags allgemein gut ausfindig machen und das probieren wir auch gleich mal aus.
1 2 3 4 5 | import bs4, requests src_url = "https://de.wikipedia.org/wiki/Thiel_und_Boerne#Folgen" soup = bs4.BeautifulSoup( requests.get(src_url).content, 'html.parser' ) span_folgen = soup.find( id="Folgen" ) span_folgen |
1] Zunächst importieren wir die Bibliothek bs4 namentlich Beautiful Soup für das Parsen der HTML Seite. Und dann noch requests, welche für den Download der Web-Seite über das HTTPS-Protokoll zuständig ist.
3] Aus dem Inhalt des herunter geladenen Dokumentes (requests.get(src_url).content) erzeugen wir dann ein BeautifulSoup Objekt (bs4.BeautifulSoup(..))..
4] … suchen nach einem Tag mit der id=“Folgen“. (soup.find( id="Folgen" ))
5] Und lassen uns das Ergebnis für unmittelbares Feedback ausgeben.

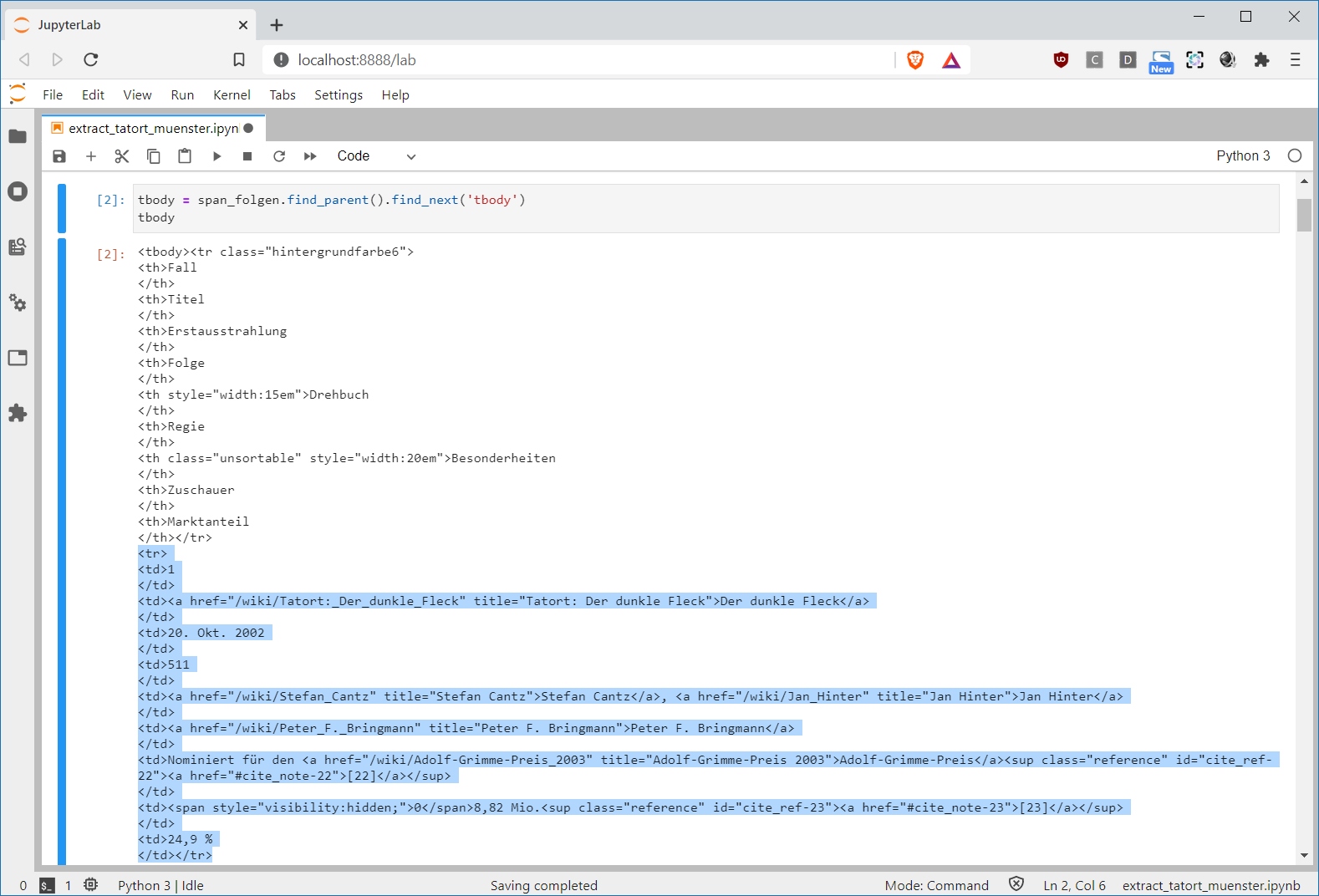
Auffinden der Titel Tabelle:
7 8 | tbody = span_folgen.find_parent().find_next('tbody') print( str(tbody)[:398] ) |
7] Das <tbody> Tag findet sich indem wir dem Anker-Tag span_folgen folgen, eine Ebene höher gehen (span_folgen.find_parent()) und von dort aus das nächste <tbody> Tag suchen (.find_next('tbody')).
8] Zur Kontrolle lassen wir uns nur die ersten 398 Zeichen ausgeben. ([:398])
Der nachfolgend blau markierte Bereich stellt den Anfang der zweiten Zeile der Tabelle dar. Die erste Zeile für Spalten-Überschriften überspringen wir später.
Alle Titel verarbeiten:
10 11 12 13 14 15 16 17 18 19 20 | import glob dest_path = "m:/dlna-m/Serien/Tatort" for row in list( tbody.findChildren( "tr", recursive=False) )[1:]: td_text = [td.get_text().strip() for td in row.find_all("td")] file = f"{dest_path}/Tatort - Münster {int( td_text[0] ):02} - {td_text[1]}" if glob.glob( f"{file}.*" ): print( "skiped:", file ) else: with open( f"{file}.txt", "w+" ) as f: print( "create:", file ) |
10] Für das Prüfen von vorhandenen Dateien nach Muster nutzen und importieren wir die Bibliothek glob. Und setzen in 11] den Zielpfad für unsere Text-Dateien.
13] Ist etwas komplexer. Denn nachdem wir alle <tr> Unterelemente von tbody suchen (tbody.findChildren(..)) und zur Liste (list(..)) zusammenfassen, bilden wir eine Schleife (for row in ..) über alle außer dem 0-ten dieser Elemente ([1:]) und verwenden sie jeweils als row weiter.
14] Aus den bereinigten Spalten-Texten (td.get_text().strip()) aller gefundenen <td> Unterelemente der Zeile row, bilden wir per List-Comprehension ([[..for td in row.find_all("td")]]) die Liste aller Spalten-Texte: td_text. Achtung! Die Nummerierung beginnt Python-typisch mit 0!
15] Der aktuelle Dateiname ohne Endung (file) wird mit Hilfe von Format-Strings (f"..") aus 3 Hauptbestandteilen gebildet. A] der Datei-Pfad bestimmt sich weitgehend aus dem Ziel-Pfad dest_path. B] Die Titel-Nummer wird aus der 0-ten Spalte gebildet (td_text[0]) indem zunächst der Integer-Wert ermittelt (int(..)) - und dann per Format-Anweisung auf 2 Stellen mit 0 aufgefüllt wird ({..:02}). C] Der Titel Name wird aus der 1-ten Spalte gewonnen ({td_text[1]}) und..
16] ... wenn bereits eine - wie die aktuell betrachtete Datei beliebiger Endung existiert (if glob.glob( f"{file}.*" )), überspringen wir sie einfach mit 17] einer Log-Meldung.
18] Anderenfalls 19] erzeugen wir die TXT-Datei gleichen Namens (with open( f"{file}.txt", "w+" ) as f) und 10] eine andere Log-Meldung.
Was dann folgende Ausgabe erzeugt:

Hiernoch einmal der Quell-Code im Ganzen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | import bs4, requests src_url = "https://de.wikipedia.org/wiki/Thiel_und_Boerne#Folgen" soup = bs4.BeautifulSoup( requests.get(src_url).content, 'html.parser' ) span_folgen = soup.find( id="Folgen" ) span_folgen tbody = span_folgen.find_parent().find_next('tbody') print( str(tbody)[:398] ) import glob dest_path = "m:/dlna-m/Serien/Tatort" for row in list( tbody.findChildren( "tr", recursive=False) )[1:]: td_text = [td.get_text().strip() for td in row.find_all("td")] file = f"{dest_path}/Tatort - Münster {int( td_text[0] ):02} - {td_text[1]}" if glob.glob( f"{file}.*" ): print( "skiped:", file ) else: with open( f"{file}.txt", "w+" ) as f: print( "create:", file ) |
- Ansicht: extract_tatort_muenster(14).html
- Download: extract_tatort_muenster(14).ipynb